在上一期的大模型美女福利导航實踐中,美女直播全婐APP免费下载為大家介紹了基於“LangChain+LLM”框架快速搭建知識增強後的問答星空機器人,並探討了提升模型內容理解和執行能力的潛在優化方向。
本期內容UCloud將為您解析參數高效微調美女福利导航(PEFT),即對已預訓練好的模型,固定住其大部分參數,而僅調整其中小部分或額外的參數,以達到與全部參數微調相近的效果。
參數高效微調方法,可大致分為三個類別:增加式方法、選擇式方法和重新參數化式方法[1]。
1 增加式方法(Additive methods)
增加式方法通過增加額外的參數或層來擴展現有的預訓練模型,且僅訓練新增加的參數。目前,這是PEFT方法中被應用最廣泛的類別。
在增加式方法中,大致分為Adapter類方法和軟提示(Soft Prompts)。2019年1月至2022年3月期間,Adapter類的方法Adapter Tuning,軟提示類的方法Prefix Tuning、P-Tuning、Prompt Tuning、P-Tuning v2相繼出現。
1.1 Adapter Tuning[2]
Adapter的架構如下:

在每一個Transformer層中的每個子層之後插入兩個串行的Adapter。在Adapter微調期間,綠色層是根據下遊數據進行訓練的,而預訓練模型的原參數保持不變。
1.1.1 Adapter的特點
Adapter 模塊主要由兩個前饋(Feed-forward)子層組成。
1. 第一個前饋子層將原始特征的維度d投影到一個更小的維度m,應用非線性函數,再投影回維度d的特征(作為Adapter模塊的輸出)。
2. 總參數量為2md + d + m。通過設置m < d,美女直播全婐APP免费下载限製了每個任務添加的參數數量。
3. 當投影層的參數初始化接近零時,根據一個skip-connection,將該模塊就初始化為近似恒等函數,以確保微調的有效性。
1.1.2 Adapter的實驗結果
使用公開的預訓練BERT作為基礎模型。Adapter微調具有高參數效率,可以生成性能強勁的緊湊模型,與完全微調相比表現相當。Adapter通過使用原始模型0.5-5%大小的參數量來微調,性能與BERT-LARGE上具有競爭力的結果相差不到1%。
1.2 Soft Prompts
早期的提示微調通過修改輸入文本來控製語言模型的行為,稱為硬提示(Hard Prompts)微調。這些方法很難優化,且受到最大模型輸入長度的限製。下圖為離散的人工設計的Prompt示例:
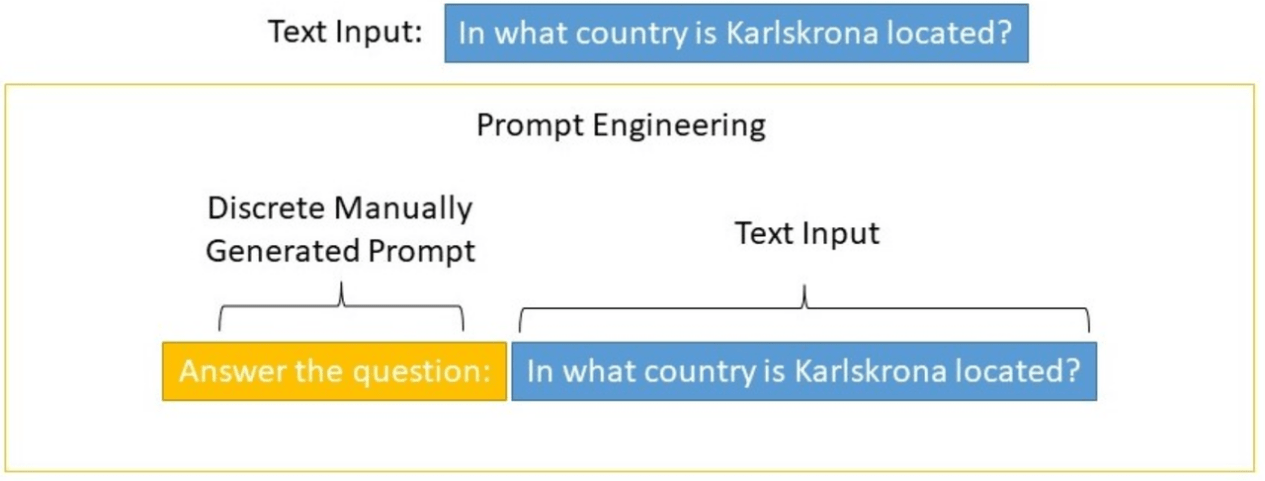
比如改變輸入形式去詢問模型:
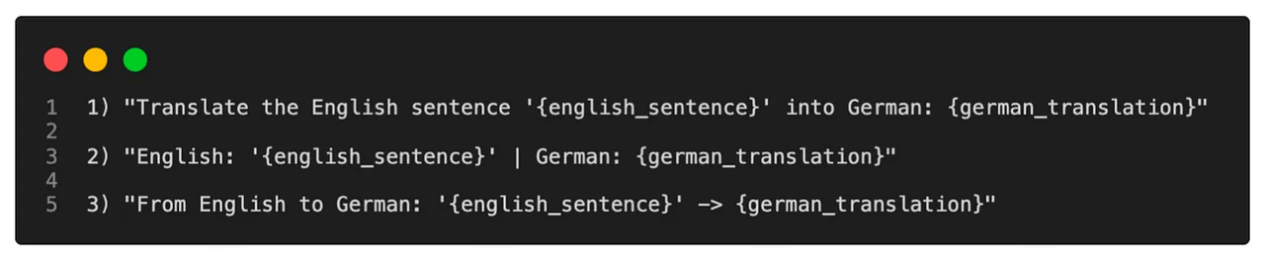
軟提示(Soft Prompts)將離散的“提示”問題轉為連續的“提示”問題,通過過反向傳播和梯度下降更新參數來學習Prompts,而不是人工設計Prompts。有僅對輸入層進行訓練,也有對所有層進行訓練的類型。下麵將介紹幾種熱門的Soft Prompts微調方法。
1.2.1 Prefix Tuning
其結構如下:

隻優化前綴(紅色前綴塊),該前綴添加到每一個Transformer Block中。
1.2.1.1 Prefix Tuning的特點
1. 凍結預訓練語言模型的參數,為每個任務存儲特定的連續可微的前綴,節省空間。
2. 訓練間增加MLP層以達到穩定。
3. 對於不同模型構造不同的Prefix。
1.2.1.2 Prefix Tuning的實驗結果
對於表格到文本任務,使用GPT-2MEDIUM和GPT-2LARGE模型。在表格到文本任務上,Prefix Tuning優於Fine-Tuning(全量微調)和Adapter-Tuning。對於摘要任務,使用BART-LARGE模型。在摘要任務上,Prefix Tuning比全量微調弱。
1.2.2 P-Tuning
其結構如下:
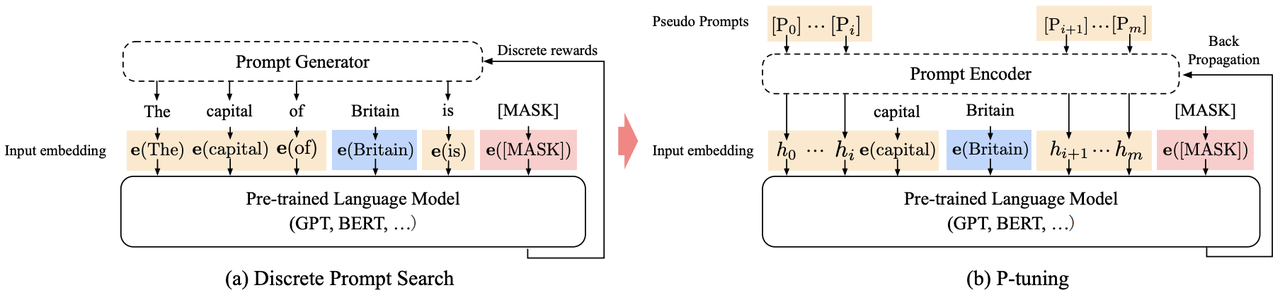

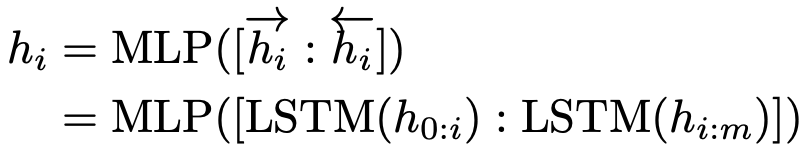
1.2.2.1 P-Tuning的特點
1. P-Tuning隻在輸入層加入可微的Virtual Token,其會自動插入到文本提示的離散Token嵌入中。
2. Virtual Token不一定作為前綴,其插入位置是可選的。
1.2.2.2 P-Tuning的實驗結果
使用的是GPT係列和BERT係列的模型。P-Tuning與全參數效果相當,且在一些任務上優於全參數微調,可以顯著提高GPT模型在自然語言理解方麵的性能,並且BERT風格的模型也可以獲得較小的增益。
1.2.3 Prompt Tuning
其結構如下:

上圖中,僅Virtual Token部分會由梯度下降法去更新參數。
1.2.3.1 Prompt Tuning的特點
1. 隻在輸入層加入Prompt,並且不需要加入MLP進行調整來解決難訓練的問題。
2. 提出了Prompt Ensembling,即通過在同一任務上訓練N個提示,也就是在同一個批次中,對同一個問題添加不同的Prompt,相當於為任務創建了N個獨立的“模型”,同時仍然共享核心語言建模參數。
1.2.3.2 Prompt Tuning的實驗結果
使用的是預訓練的各種T5模型。在流行的SuperGLUE基準測試中,Prompt Tuning的任務性能與傳統的模型調優相當,且隨著模型規模的增加,差距逐漸減小。在零樣本領域遷移中,Prompt Tuning可以改善泛化性能。
1.2.4 P-Tuning v2
其結構如下:
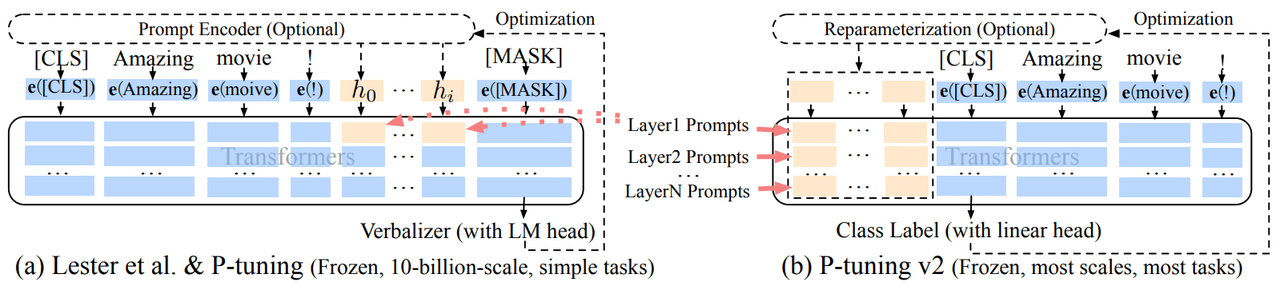

1.2.4.1 P-Tuning v2的特點
P-Tuning v2每一層的輸入都加入了Tokens,允許更高的任務容量同時保持參數效率;且添加到更深層的提示對模型的預測有更直接的影響。
1.2.4.2 P-Tuning v2的實驗結果
使用的是BERT係列和GLM係列模型。P-Tuning v2是一種在不同規模和任務中都可與微調相媲美的提示方法。在NLU任務中,整體上P-Tuning v2與全量微調的性能相差很小。
2 選擇式方法
選擇性方法對模型的現有參數進行微調,可以根據層的深度、層類型或者甚至是個別參數進行選擇。
2.1 BitFit
2022年9月5日,BitFit出現,這是一種稀疏微調方法,僅修改模型的Bias(偏置項)或其中的子集。
2.1.1 BitFit的特點
1. 凍結大部分Transformer編碼器的參數,隻訓練偏置項和任務特定的分類層。
2. 優化的偏置項參數包括Attention模塊中計算Query、Key、Value時,計算MLP層時,計算Layernormalization層時遇到的偏置項參數。
3. 每個新任務隻需要存儲偏置項參數向量(占總參數數量的不到0.1%)和任務特定的最終線性分類器層。
2.1.2 BitFit的實驗結果
使用公開可用的預訓練BERTBASE、BERTLARGE和RoBERTaBA模型。BitFit微調結果不及全量參數微調,但在極少數參數可更新的情況下,遠超Frozen(凍結模型參數)方式。
3 重新參數化方法
基於重新參數化的高效微調方法利用低秩表示來最小化可訓練參數的數量,其中包括2021年10月到2023年3月間出現的LoRA和AdaRoLA方法。
3.1 LoRA
該方法認為模型權重矩陣在特定微調後具有較低的本征秩,故基於秩分解的概念,將預訓練模型的現有權重矩陣分成兩個較小的矩陣。

3.1.1 LoRA的特點
1. 將矩陣乘積BA加到原模型參數矩陣W上可以避免推理延遲。
2. 可插拔的低秩分解矩陣模塊,方便切換到不同的任務。
3.1.2 LoRA的實驗結果
使用的模型是RoBERTa、DeBERTa、GPT-2、GPT-3 175B。在多個數據集上,LoRA在性能上能和全量微調相近,且在某些任務上優於全量微調。
3.2 AdaLoRA
3.2.1 AdaLoRA的特點
該方法基於權重矩陣的重要性而自適應調整不同模塊的秩,節省計算量,可理解為LoRA的升級版。
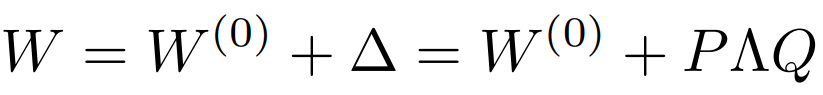
AdaLoRA的做法是讓模型學習SVD分解的近似。在損失函數中增加了懲罰項,防止矩陣P和Q偏離正交性太遠,以實現穩定訓練。
3.2.2 AdaLoRA的實驗結果
使用的模型是DeBERTaV3-base 和BART-large模型。AdaLoRA的性能通常高於參數量更高的方法。其中,AdaLoRA在0.32M微調參數時,在CoLA數據集上達到了70.04的Mcc分數。
4 參數微調方法小結
以上幾類參數高效微調方法,各有千秋。Adapter方法在預訓練模型的層中插入可訓練模塊的形式簡單,但增加推理延時。Soft Prompts方法避免了人工“硬提示”的局限性,卻可能難收斂。
Soft Prompts方法中,Prefix Tuning率先提出可用梯度下降法優化的的Tokens,而 P-Tuning、Prompt Tuning、P-Tuning v2相繼作出不同的改變,比如:
1. 加入的Tokens:P-Tuning僅限於輸入層,而Prefix-Tuning在每一層都加。
2. P-Tuning和Prompt Tuning僅將連續提示插入到輸入嵌入序列中,而Prefix Tuning的“軟提示”添加在每一個Transformer Block中。
3. Prompt Tuning不需要額外的MLP來解決難訓練的問題,P-Tuning v2移除了重參數化的編碼器。
BitFit方法隻更新模型內部偏置項參數所以訓練參數量很微小,但整體效果比LoRA、Adapter等方法弱。LoRA方法不存在推理延時,但無法動態更新增量矩陣的秩,不過改進版AdaLoRA解決了這個問題。
5 AdaLoRA方法的實驗
5.1 實驗模型為ChatGLM2-6B
官網代碼在Git Clone http://github.com/THUDM/ChatGLM2-6B,可去Hugging Face下載其模型文件。應用AdaLoRA之後的模型訓練參數僅占總參數的0.0468%。

5.2 實驗數據為中文醫療問答數據
下載鏈接為http://github.com/Toyhom/Chinese-medical-dialogue-data,包括兒科、外科等問答數據,數據中會有建議去醫院看病之類的文字。此處選取兒科和外科的數據分別10000條數據作為訓練數據集,將文件保存為json格式。
5.2.1 構造數據集
文件為dataset.py。

5.2.2 訓練代碼
1. 文件為FT.py。

2. 配置文件config_accelerate.yml

3. 執行文件run.sh

5.2.3 測試代碼

結果為:

6 結語
除了以上3大類方法之外,還有混合參數高效微調方法,其是綜合了多種PEFT類別思想的方法。比如MAM Adapter同時結合了Adapter和Prompt-Tuning的思想,UniPELT綜合了LoRA、Prefix Tuning和Adapter的思想。混合參數高效微調方法大概率優於單個高效微調方法,但訓練參數和推理延時的都增加了。下次將會對大模型的加速並行框架進行探討,歡迎大家持續關注!
相關文章
[1]《Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning》
[2]《Parameter-Efficient Transfer Learning for NLP》
[3]《Prefix-Tuning: Optimizing Continuous Prompts for Generation》
[4]《GPT Understands, Too》
[5]《The Power of Scale for Parameter-Efficient Prompt Tuning》
[6]《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》
[7]《BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models》
[8]《LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》
[9]《ADAPTIVE BUDGET ALlocations FOR PARAMETEREFFICIENT FINE-TUNING》
星空人工智能美女福利导航網 倡導尊重與保護知識產權。如發現本站文章存在版權等問題,煩請30天內提供版權疑問、身份證明、版權證明、聯係方式等發郵件至1851688011@qq.com美女直播全婐APP免费下载將及時溝通與處理。!:首頁 > 數字經濟 » 優刻得大模型美女福利导航實踐(四)|參數高效微調美女福利导航解析及AdaLoRA的應用